Dados de Coleta
O sistema e-Nose coleta sinais químicos através de um conjunto de sensores. Esses sinais são registrados ao longo do tempo, processados e utilizados para identificar padrões associados a diferentes condições das amostras analisadas.
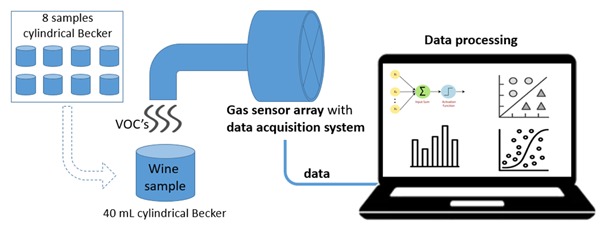
Sistema de aquisição e sensores
O diagrama apresenta o funcionamento geral do sistema e-Nose. As amostras liberam compostos orgânicos voláteis que são captados pelo conjunto de sensores de gás. Os sinais gerados são enviados ao sistema de aquisição e posteriormente processados computacionalmente para análise dos padrões químicos.
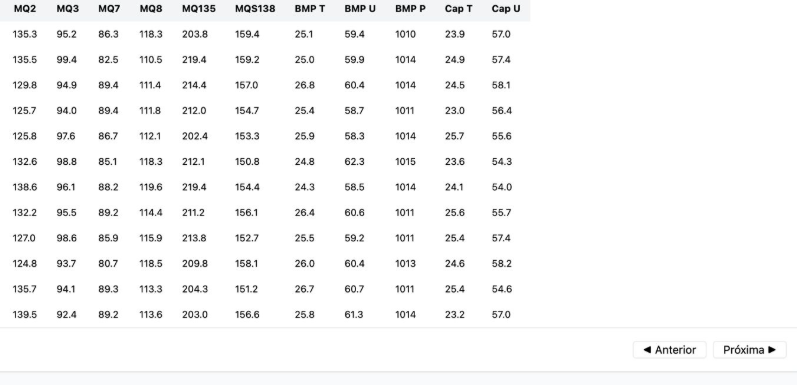
Dados e Análises
A tabela apresenta um exemplo de amostra dos dados captados pelos sensores do sistema e-Nose durante os experimentos. Cada coluna corresponde a um sensor ou variável ambiental, incluindo sensores MQ, temperatura, umidade e pressão atmosférica.
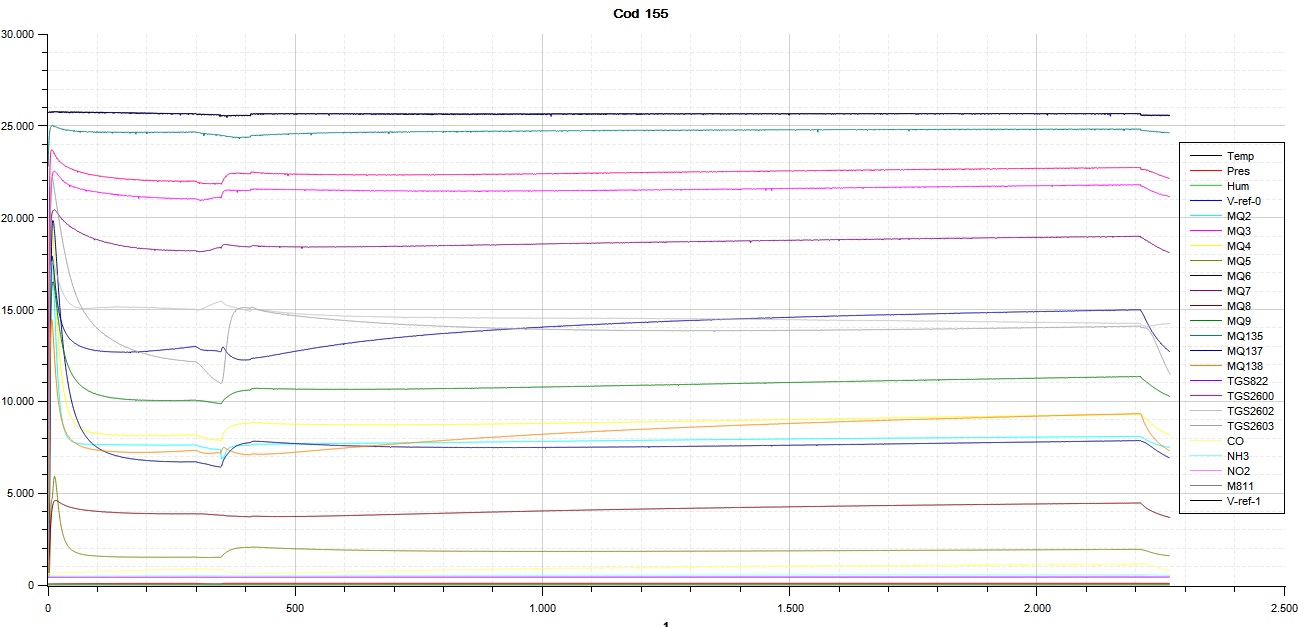
Análise de classificação
Após o processamento dos sinais, algoritmos de aprendizado de máquina são aplicados para identificar padrões. O modelo utiliza os dados captados pelos sensores para diferenciar automaticamente as classes analisadas.
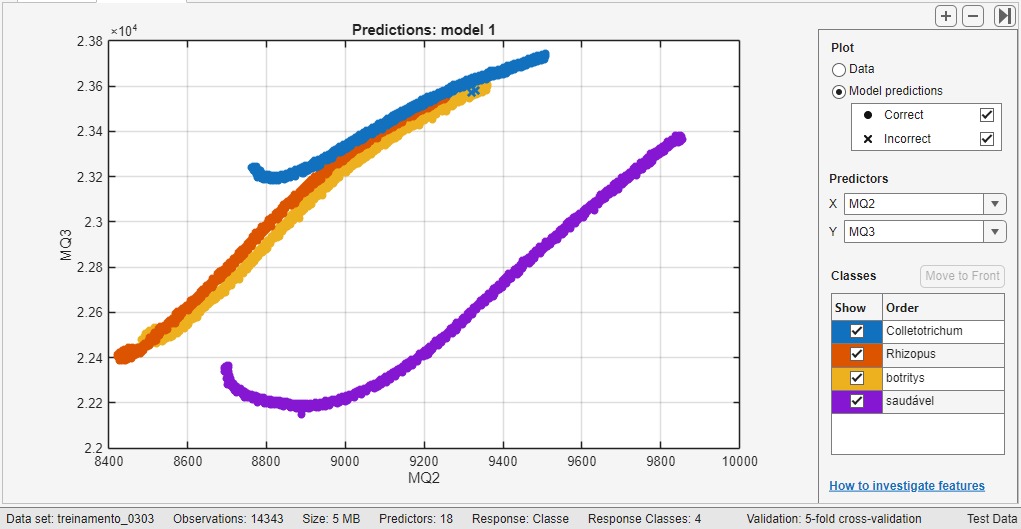
Separação entre classes
Este gráfico apresenta a relação entre dois sensores do sistema. Os pontos coloridos representam diferentes condições das amostras analisadas. A formação de grupos indica que os padrões químicos captados podem ser diferenciados.
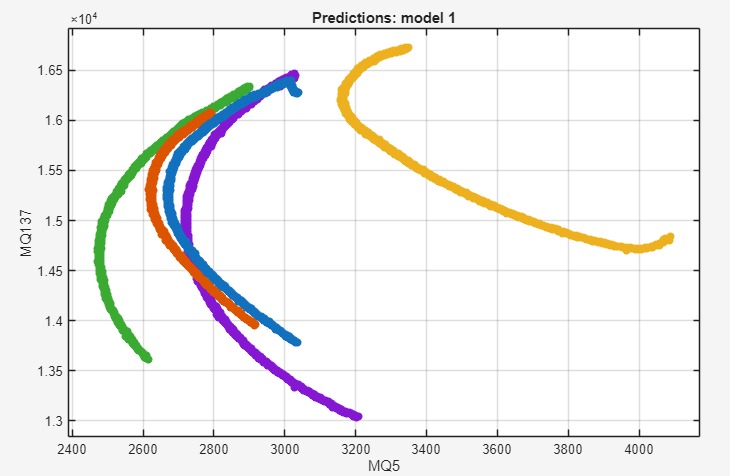
Distribuição dos padrões
Ao combinar diferentes sensores, é possível observar como os dados se distribuem no espaço de características. Essa representação ajuda a visualizar a separação entre diferentes estados das amostras.
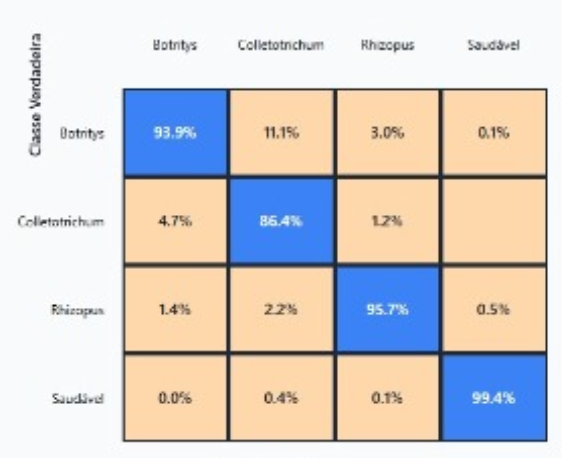
Matriz de confusão do modelo
A matriz de confusão mostra o desempenho do modelo de classificação utilizado no sistema e-Nose. Cada célula representa a porcentagem de amostras classificadas corretamente ou incorretamente entre as diferentes classes analisadas.
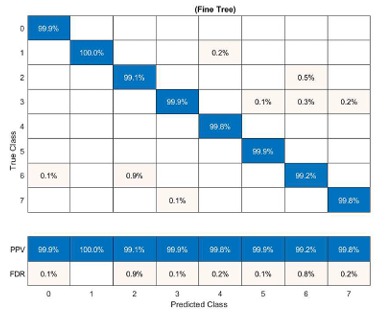
Avaliação do modelo de classificação
A matriz de confusão detalha o desempenho do algoritmo de aprendizado de máquina utilizado. Os valores na diagonal representam classificações corretas, enquanto valores fora da diagonal indicam possíveis erros entre classes.
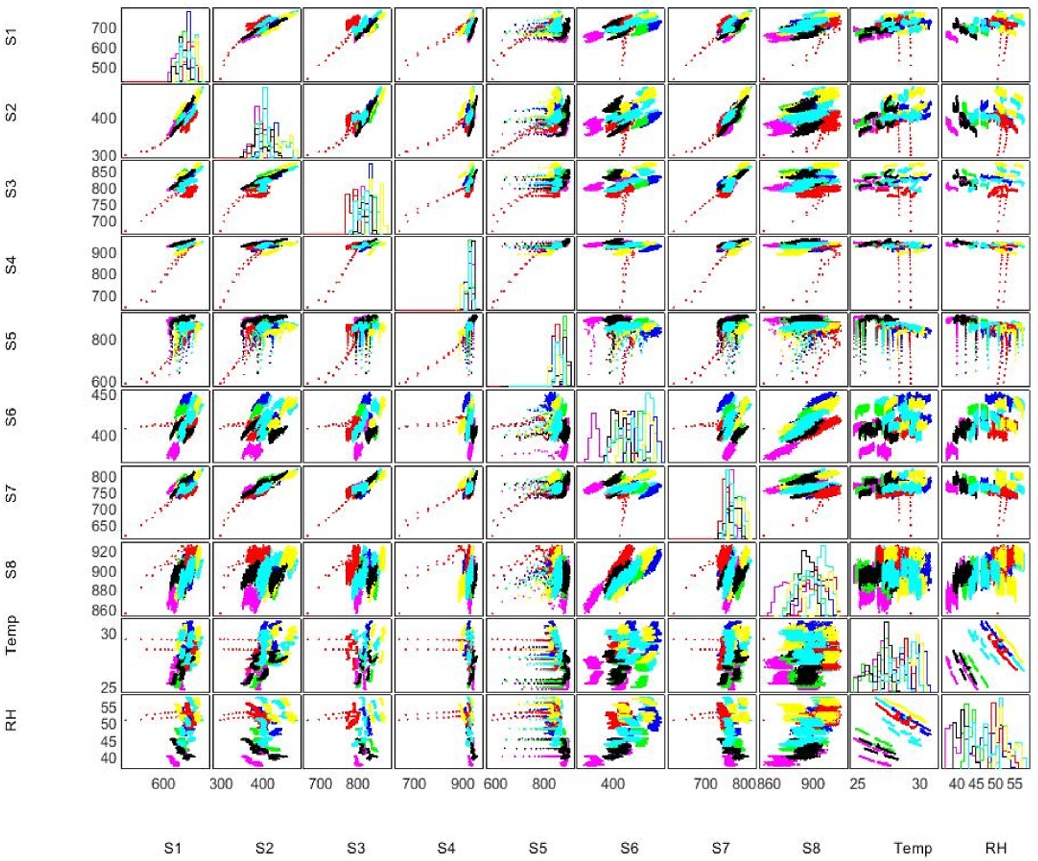
Relação entre sensores e variáveis ambientais
O gráfico apresenta a relação entre diferentes sensores do sistema e variáveis ambientais como temperatura e umidade. A visualização permite observar padrões, correlações e a distribuição dos dados coletados durante os experimentos.